
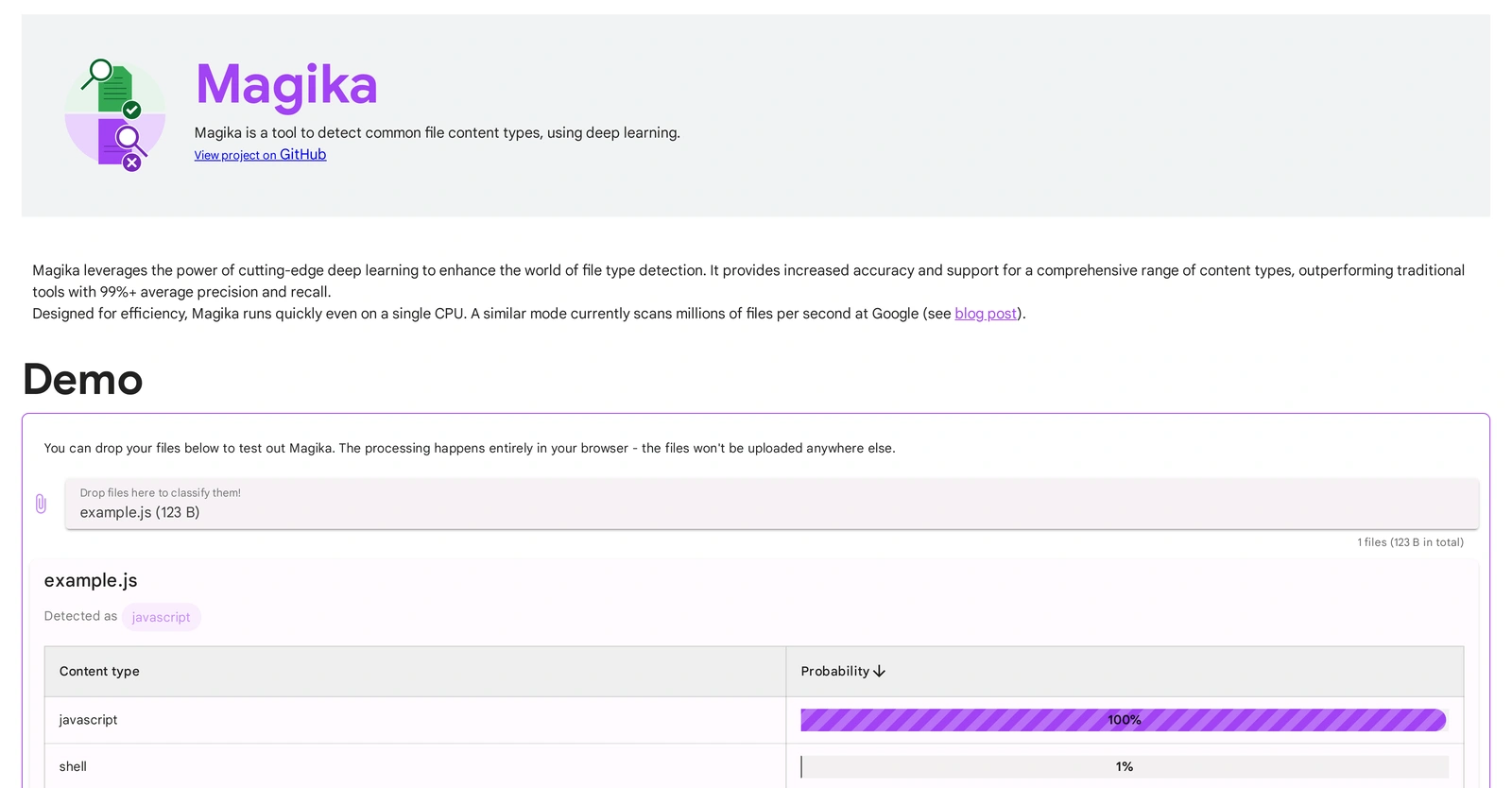
Magika is a deep learning-based tool for detecting and classifying various file content types. Developed by Google, it’s designed to outperform traditional file type detection tools by providing enhanced accuracy across a broad range of content types. Magika is designed for efficiency, allowing for quick operation even on a single CPU. Users can test out Magika’s capabilities from their browser. Uploaded files remains secure as the processing is entirely performed browser-side with no uploads to external servers. A unique feature of Magika is its installability as a Python package, allowing users to run it readily from their command line. It can also be leveraged in Python or JavaScript codebases, making it a versatile tool in a developer’s kit. Magika is a game-changer that allows precise file content type detection with comprehensive support including language-specific files, executables, document types, image and video data, and audio bitstream data, among others. Reports indicate that a similar version of Magika is in use at Google, scanning millions of files per second for accurate content-type tagging. Plans are underway to release a detailed paper explaining how Magika was trained and its performance on large datasets.Despite its capabilities, users should note that Magika is designed to output a single content type for a file, therefore polyglot files will not be mapped to two or more categories. Despite this, it remains a powerful tool in content type detection using deep learning. For users wanting to cite Magika, a citation guide is available on the project’s GitHub page.





Leave a Reply